
Track 1¶
Download part1 and part 2 of the data from Zenodo - To obtain the data for this track you are requested to complete a Data User Agreement. Please follow the instructions reported in Zenodo. After our approval of your request, you will be granted access to the data download page.
The dataset includes the following datasets:
-
MSSEG-1 [Commowick et al., 2018],
-
ISBI [Carass et al., 2017],
-
PubMRI [Lesjak et al., 2017]
-
Lausanne (private, not released for privacy reasons), provided by the Swiss universities of Lausanne and Basel
The private dataset is used for the external evaluation of the challenge submissions. A detailed summary of the provenance of the patient scans, scanner types, magnetic field strengths and original image resolution is given in Table 1.

Preprocessing¶
The supplied data have already undergone our preprocessing and do not need further preprocessing steps.
Our preprocessing includes de-noising, skull-stripping after registering the T1-weighted to FLAIR, bias field correction and interpolation to a 1mm iso-voxel space. The ground truth masks are also interpolated to the 1mm iso-voxel space and are obtained as a consensus of multiple expert annotators (and as a single mask for Best and Lausanne, which have 2 annotators only) .
The data is split into:
-
In-domain splits: Trn (training), Evl_in (evaluation) and Dev_in (development)
-
Out-of-distribution shifted splits: Dev_out (shifted development) and Evl_out (shifted evaluation)
File structure¶
First level directories represent the devision by the source datasets. Second level directories represent the splits. To obtain the full training set combine data from ISBI/Trn/ and MSSeg/Trn. The third level directories contain the modalities: FLAIR, gt (ground truth), fg_mask (foreground mask), T1 (T1-weighted).
Track 2¶
The Shifts vessel power estimation dataset consists of measurements sampled every minute from sensors on-board a merchant ship over a span of 4 years, cleaned and augmented with weather data from a third-party provider.
The task is to predict the ships main engine shaft power, which can be used to predict fuel consumption given an engine model, from the vessel's speed, draft, time since last dry dock cleaning and various weather and sea conditions. The following table summarizes the features available in the time-series given in a tabular form.
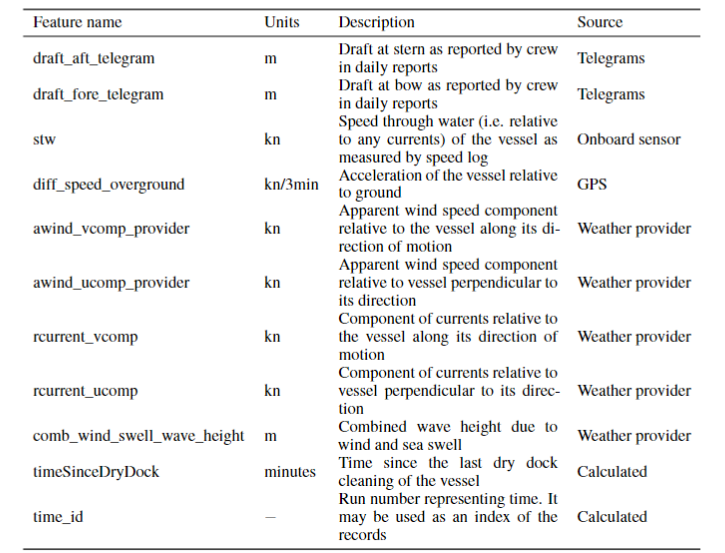
Uncertainty in the data arises due to sensor noise, measurement and transmission errors, and uncertainty in historical weather. Distributional shift arises from hull performance degradation over time due to fouling, sensor calibration drift, and variations in non-measured sea conditions such as water temperature, salinity etc. which vary in different regions and times of year.
To provide a standardized benchmark, we have created a canonical partition on the dataset into in-domain train, development and evaluation as well as distributionally shifted development and evaluation splits, as is the standard in Shifts. The dataset is partitioned along two dimensions: wind speed and time, as illustrated in the following figure. Wind speed serves as a proxy for unmeasured components of the sea state, while partitioning in time aims to capture effects such as hull fouling and sensor drift.

In addition to the standard canonical benchmark we are providing a synthetic benchmark dataset created using an analytical physics-based vessel model. The synthetic dataset contains the same splits and input features as in the canonical dataset, but the target power labels are replaced with predictions of a physics model. Given that vessel physics are fairly well understood, it is possible to create a model of reality which captures most relevant factors of variation and model them robustly.

A significant advantage of the synthetic dataset is that is allows generating a generalisation dataset that can cover the convex hull of possible feature combinations. Specifically, additional data points (2.5 million) are created by applying the model to input features independently and uniformly sampled from a predefined range. The idea is to sample from the convex hull of the full range of possible conditions, so all samples are i.i.d., and rare combinations of conditions are equally represented. For example, vessels are less likely to adopt high speeds in severe weather, which could lead ML models to learn a spurious correlation. This bias would not be detected during the evaluation on real data as the same correlation would be present. Evaluating a candidate model on this generalisation task thus tests its ability to properly disentangle causal factors and generalise to unseen conditions. This generalisation set can enable assessing model robustness with greater coverage, even if on a simplified version of reality.
The real and synthetic datasets can be used together. The real-world performance and hyper-parameter exploration can be done using the real data, while the synthetic generalisation set can be used to more broadly assess generalisation to unseen feature variations.